先申明,这篇文章的核心内容是抄自这篇,易百教程这个网站上好多很好的学习资料。这篇想借着学习Elasticsearch的机会顺便再理解下RESTful、学习一下curl的使用。好了,进入正文吧。
简介
Elasticsearch是一个高度可扩展的开源搜索引擎,它可以使用RESTful API访问,使用JSON来存储数据。它是用Java开发的。
上面是从网上抄的,我作为初学者来说,先不管什么可扩展、分布式。Elasticsearch给我的第一印象就是一个类似MongoDB的非关系型数据库。下面先抄一个表,来对应一下关系型数据库中的相关概念:
| Elasticsearch | 关系型数据库 |
|---|---|
| 索引 | 数据库 |
| 碎片 | 碎片 |
| 映射 | 表 |
| 字段 | 字段 |
| JSON对象 | 元组 |
既然Elasticsearch是一个数据库了,那就免不了增、删、改、查操作了,我们记住了,这里都是通过RESTful进行的。那么是时候了解一下RESTful了。
RESTful
RESTful是什么,我是很难说清楚,直接引用百度百科上的一段话吧:
一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
所以我感觉是什么不重要了,重要的是如何用。我的理解就是使用标准HTTP方法,进行与远程应用之间的数据交互,这点就类似于我们使用mysql客户端对mysql数据库进行增删改查操作,RESTful使用POST、DELETE、PUT、GET等方法进行数据的增删改查。好了,简单记一下每个方法的含义:
- POST:创建资源
- DELETE:删除资源
- PUT:更新资源(如果没有就创建)
- GET:查询资源
接下来,就通过curl工具进行RESTful操作Elasticsearch,简单学习之。
下载安装配置运行
到https://www.elastic.co/cn/这个网站上下载。
下载完成后解压缩就能用了,不用安装。
默认不需要修改配置,如果要修改配置怎么办,例如默认的9200端口已经被其他程序占用了。这时要到Elasticsearch主目录下的config/elasticsearch.yml下修改如下:1
http.port: 9300
其他如修改数据过期时间等都是都在这里,这里不试了,直接采用默认。
运行就是到bin目录下执行elasticsearch命令就可以了。因为是Java开发的,所以需要java环境,最好是1.8的。
CRUD
CRUD是什么?就是前面说的增删改查的简写:create/retrive/update/delete。以后CRUD这个说法会经常出现。
创建索引
这里不自己理解了,直接引用:
在ElasticSearch索引中,对应于CRUD中的“创建”和“更新” - 如果对具有给定类型的文档进行索引,并且要插入原先不存在的ID。 如果具有相同类型和ID的文档已存在,则会被覆盖。
要索引第一个JSON对象,我们对REST API创建一个PUT请求到一个由索引名称,类型名称和ID组成的URL。 也就是:http://localhost:9200/<index>/<type>/[<id>]。
索引和类型是必需的,而id部分是可选的。如果不指定ID,ElasticSearch会为我们生成一个ID。 但是,如果不指定id,应该使用HTTP的POST而不是PUT请求。
索引名称是任意的。如果服务器上没有此名称的索引,则将使用默认配置来创建一个索引。
至于类型名称,它也是任意的。 它有几个用途,包括:
- 每种类型都有自己的ID空间。
- 不同类型具有不同的映射(“模式”,定义属性/字段应如何编制索引)。
- 搜索多种类型是可以的,并且也很常见,但很容易搜索一种或多种指定类型。
举例,要创建一个索引,这里使用索引的名称为movies,类型名称(movie)和id(1),并按照上述模式使用JSON对象在正文中进行请求。
1 | curl -XPUT "http://localhost:9200/movies/movie/1" -d' |
更新索引
直接上curl操作的例子:1
2
3
4
5
6
7curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
引用:
ElasticSearch的响应结果与前面的大体上一样,但有一点区别,结果对象中的_version属性的值为2,而不是1。版本号(_version)可用于跟踪文档已编入索引的次数。它的主要目的是允许乐观的并发控制,因为可以在索引请求中提供一个版本,如果提供的版本高于索引中的版本,ElasticSearch将只覆盖文档内容,ID值不变,版本号自动添加。
由ID获取文档
简单的做法是向同一个URL发出一个GET请求,URL的ID部分是强制性的。通过ID从ElasticSearch中检索文档可发出URL的GET请求:http://localhost:9200/<index>/<type>/<id>。
例如:1
curl -XGET "http://localhost:9200/movies/movie/1" -d''
删除文档
为了通过ID从索引中删除单个指定的文档,使用与获取索引文档相同的URL,只是这里将HTTP方法更改为DELETE。
1 | curl -XDELETE "http://localhost:9200/movies/movie/1" -d'' |
响应对象包含元数据方面的一些常见数据字段,以及名为“_found”的属性,表示文档确实已找到并且操作成功。
在执行DELETE调用后切换回GET,可以验证文档是否确实已删除。
搜索
搜索就是查询了。这是Elasticsearch的核心,因为人名字里就带search这个单词了。
为了演示搜索,用curl再向Elasticsearch添加两条记录:
1 | curl -XPUT "http://localhost:9200/movies/movie/2" -d' |
好了,现在把三部著名电影(教父、杀死比尔、杀死一只知更鸟)信息加入Elasticsearch了,开始练习搜索。
_search端点
又是直接引用:
现在已经把一些电影信息放入了索引,可以通过搜索看看是否可找到它们。 为了使用ElasticSearch进行搜索,我们使用_search端点,可选择使用索引和类型。也就是说,按照以下模式向URL发出请求:
/ /_search。其中,index和type都是可选的。
换句话说,为了搜索电影,可以对以下任一URL进行POST请求:
- http://localhost:9200/_search - 搜索所有索引和所有类型。
- http://localhost:9200/movies/_search - 在电影索引中搜索所有类型
- http://localhost:9200/movies/movie/_search - 在电影索引中显式搜索电影类型的文档。
因为我们只有一个单一的索引和单一的类型,所以怎么使用都不会有什么问题。为了简洁起见使用第一个URL。
搜索请求正文和ElasticSearch查询DSL
DSL格式:1
2
3
4
5{
"query": {
//Query DSL here
}
}
基本自由文本搜索
查询电影信息中带kill的:1
2
3
4
5
6
7
8curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"query_string": {
"query": "kill"
}
}
}'
上面是DSL查询方式,看直接url传参数怎么查:1
curl -XGET 'localhost:9200/_search?q=kill'
指定搜索的字段
在前面的例子中,使用了一个非常简单的查询,一个只有一个属性“query”的查询字符串查询。 如前所述,查询字符串查询有一些可以指定设置,如果不使用,它将会使用默认的设置值。
这样的设置称为“fields”,可用于指定要搜索的字段列表。如果不使用“fields”字段,ElasticSearch查询将默认自动生成的名为“_all”的特殊字段,来基于所有文档中的各个字段匹配搜索。
下面就查一个指定字段的:1
2
3
4
5
6
7
8
9curl -XPOST "http://localhost:9200/_search" -d'
{
"query": {
"query_string": {
"query": "kill",
"fields": ["title"]
}
}
}'
这个例子直接url传参数的查询是这样的:1
curl -XGET 'localhost:9200/_search?q=title:kill'
过滤查询
直接上个例子,剩下的还是看原文吧。
1 | curl -XPOST "http://localhost:9200/_search" -d' |
ELK入门
本章的内容主要来自下面这两篇:
https://dunwu.github.io/blog/2017/11/14/javatool/elk/
https://www.cnblogs.com/huangxincheng/p/7918722.html
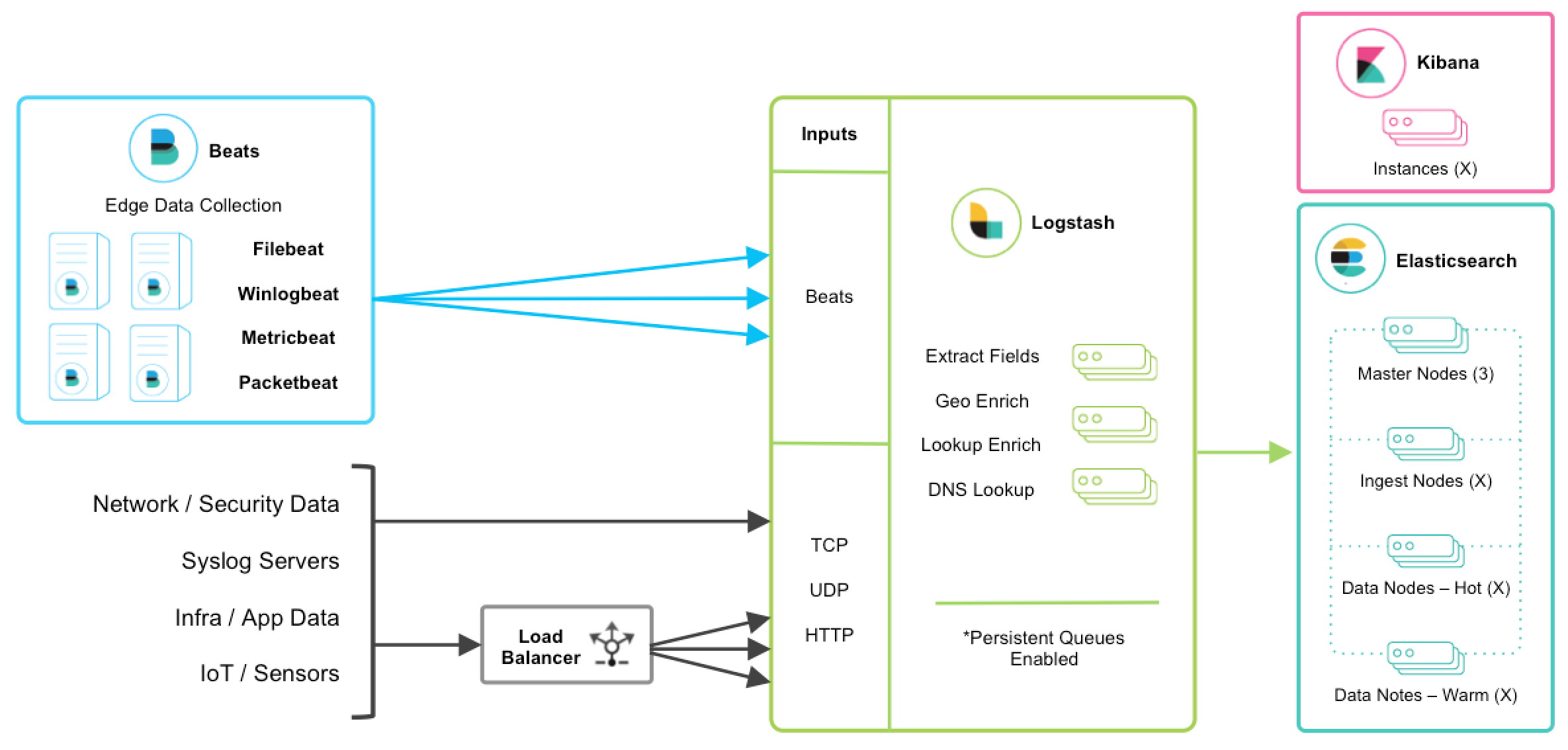
ELK是elastic公司的三款产品Elasticsearch、Logstash和Kibana的首字母组合。
- Elasticsearch是一个基于Lucene构建的开源、分布式的RESTful搜索引擎。
- Logstash传输和处理你的日志、事务或其他数据。
- Kibana将Elasticsearch的数据分析并渲染为可视化的报表。
算了,不抄了,用到时还是直接参考人家的文章吧。->_->
我也引一张ELK的架构图: